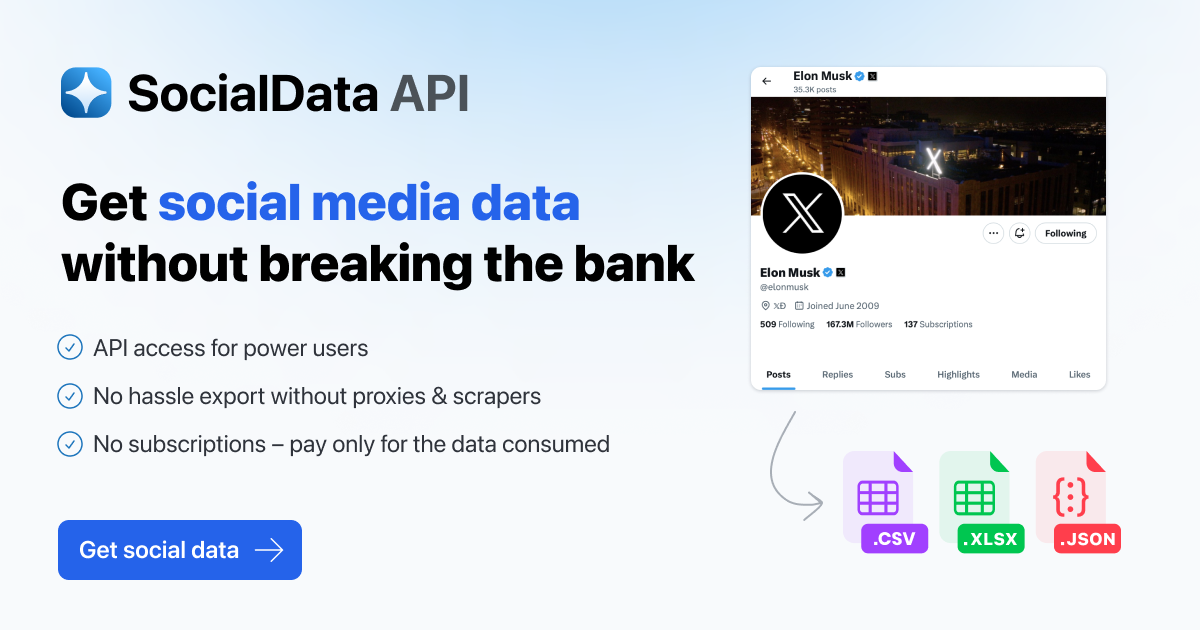
SatJan3115:19:152026 <2> FileUtils.cc(SDir):88THROW: open failed path:/home/.snapshotserrno:2 (No such file or directory) SatJan3115:19:152026 <2> Snapshot.cc(initialize):427CAUGHT: open failed path:/home/.snapshotserrno:2 (No such file or directory)
日志清晰地显示了 open failed path:/home/.snapshots errno:2 (No such file or directory)。这表明 /home 目录下缺少 .snapshots 子卷,导致 Snapper 在尝试删除相关快照时找不到其存储位置,从而无法完成配置删除操作。
Copyq 在 kde 环境下全局快捷键不起作用,可能的原因是 copy 自启动之后与全局快捷键有冲突,具体现象是在 copyq 开启 auto start 之后,在 shortcut 系统设置里会出现两个 copyq 的快捷键设置,一个在 Applications 下面,一个在 System Services 。
这两个程序都会去注册全局快捷键,然后就会提示下面的错误
1
Dec2509:16:16ThinkPad copyq[2156]: Warning: [qt.qpa.services] Failed to register with host portal QDBusError("org.freedesktop.portal.Error.Failed", "Could not register app ID: Connection already associated with an application ID")
我中途研究了一下 appleboy/ssh-action 的用法,想看看它是否支持多台服务器,但最终发现它不符合我的需求。我还查了一下 GitHub Actions 目前是否支持 YAML 锚点。最后我问了 Copilot:“Is this github action code a bit redundant, is there room for optimization?”
实际操作流程: a. 设置通道为非阻塞模式。 b. 将多个通道注册到一个选择器上。 c. 线程调用选择器的 select()方法。 d. 选择器返回已经就绪的通道。 e. 线程对就绪的通道执行 I/O 操作。
A context switch can occur while the kernel is executing a system call on behalf of the user. If the system call blocks because it is waiting for some event to occur, then the kernel can put the current process to sleep and switch to another process. For example, if a system call requires a disk access, the kernel can opt to perform a context switch and run another process instead of waiting for the data to arrive from the disk. Another example is the system call, which is an explicit request to put the calling process to sleep. In general, even if a system call does not block, the kernel can decide to perform a context switch rather than return control to the calling process.
实际操作流程: a. 设置通道为非阻塞模式。 b. 将多个通道注册到一个选择器上。 c. 线程调用选择器的 select()方法。 d. 选择器返回已经就绪的通道。 e. 线程对就绪的通道执行 I/O 操作。
A context switch can occur while the kernel is executing a system call on behalf of the user. If the system call blocks because it is waiting for some event to occur, then the kernel can put the current process to sleep and switch to another process. For example, if a system call requires a disk access, the kernel can opt to perform a context switch and run another process instead of waiting for the data to arrive from the disk. Another example is the system call, which is an explicit request to put the calling process to sleep. In general, even if a system call does not block, the kernel can decide to perform a context switch rather than return control to the calling process.